


Why multi-country studies need more than standardized sampling, translated surveys, and identical fieldwork plans.
Global research often starts with a logical goal: create one study design, run it across multiple markets, and compare the results to make decisions. For insights teams, brand leaders, agencies, and procurement teams, this is efficient and attractive. One questionnaire. One sampling framework. One fieldwork plan. One view of the world.
But in practice, multi-country research rarely fails because buyers want consistency. It fails when consistency is confused with sameness.
A study fielded in the USA, UK, Germany, India, and Brazil might ask the same business question. However, the local realities shaping the answers can be meaningfully different. Audience availability, category familiarity, language interpretation, device behavior, incentive expectations, privacy sensitivity, and cultural response styles vary market by market. When these differences are ignored, a study may look globally standardized while producing locally distorted data.
The standard for multi-country research is not identical execution. The standard is comparable insight. Comparable insight requires an operating model that protects the core strategic question while adapting tactical execution to local market realities.
The False Comfort of a Single Global Design

Global trackers, segmentation studies, concept tests, customer experience programs, and brand health monitors all depend on cross-market comparability. Buyers need confidence that differences in the data reflect actual differences in consumer, business, or healthcare behavior, not differences created by uneven fieldwork execution.
That is where the risk begins. A global study can use the same questionnaire and still deliver uneven meaning. A translated survey can preserve words while weakening intent. A consistent quota plan can work in a market with high audience availability but force quality trade-offs in a market where that audience is scarce. A sample source can perform well in one country and introduce risk in another.
Industry guidance from ESOMAR and GRBN on online sample quality points to a clear principle: sample quality depends on provider practices, participant validation, data quality, and operational controls. ESOMAR’s 37 Questions also exists to help buyers evaluate provider practices, sample sources, data quality, and the issues supplier answers should cover.
In multi-country research, these expectations become more important because quality risk does not appear evenly across markets. A single global template can mask local execution risk until the data is already compromised.
Translation is Not Localization
The most common tactical error in global market research is assuming that translation equals localization.
The objective is not simply to convert words. It is to preserve meaning, relevance, interpretation, and comprehension across cultures. Cross-cultural adaptation research emphasizes that multi-country survey studies require careful translation and cultural adaptation to maintain validity and reliability. The European Social Survey also aims for equivalence across languages, while GESIS guidance on questionnaire translation highlights cultural adequacy, response scales, consistency, linguistic correctness, and layout as key issues in cross-national research.
This matters in commercial research. A product benefit, brand attribute, purchase-intent question, satisfaction scale, or healthcare experience metric can carry different weight depending on geography. Words like “premium,” “trusted,” “innovative,” “convenient,” or “healthy” may activate different assumptions in different markets. A rating scale that feels standard in one market may encourage midpoint responses in another. A direct question may work in one culture and feel uncomfortable in another.
Standardizing language without localizing meaning is not efficiency. It is a potential failure point.
Three Tactical Failure Points in Multi-Country Studies
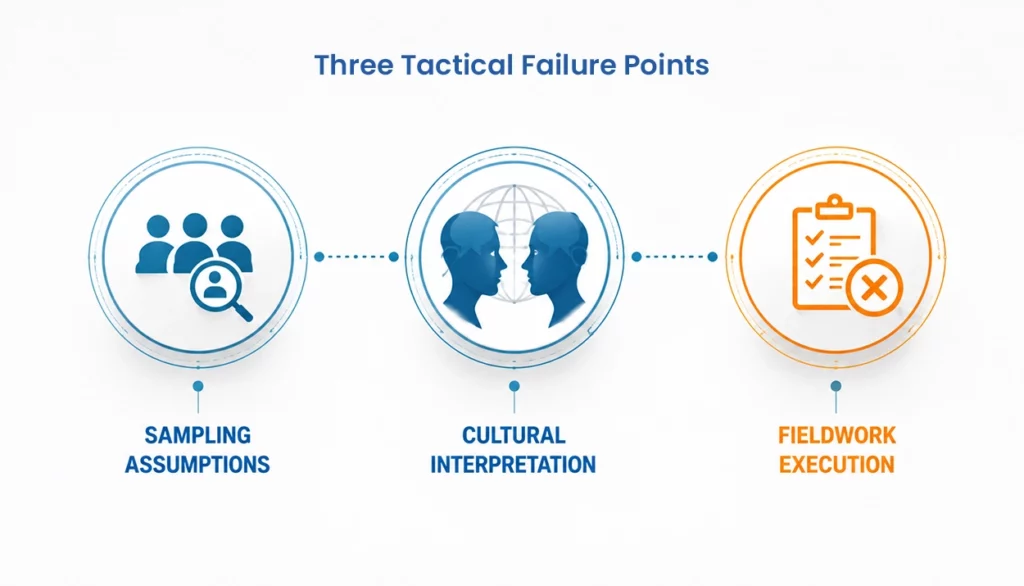
Multi-country operations typically break down in three areas: sampling assumptions, cultural interpretation, and fieldwork execution.
The first failure point is sampling. Feasibility cannot be averaged globally. An incidence rate that holds in the USA may not hold in Germany. A B2B audience definition may work in the UK but require different role validation in Japan. Healthcare access may vary by specialty, local compliance norms, respondent availability, and incentive expectations. If a partner applies blanket sampling assumptions, the weakest markets can distort the entire dataset.
The second failure point is cultural interpretation. Respondents bring local category knowledge and cultural response habits into the survey. Research on cross-cultural response styles highlights that acquiescent responding, extreme responding, middle-category responding, and socially desirable responding can vary across cultures and may introduce response bias. If these behaviors are not considered, buyers can mistake a response-style effect for a genuine market insight.
The third failure point is fieldwork execution. Survey length tolerance, mobile-first behavior, time-of-day participation, privacy sensitivity, panel engagement, and device usage can differ by country. When fieldwork falls behind schedule, the temptation is to add sources, loosen criteria, or extend fieldwork without fully diagnosing the local issue. The study may complete, but comparability can weaken.
How To Vet a Multi-Country Fieldwork
To protect both global consistency and local accuracy, buyers should pressure-test how a partner manages multi-country research quality before fieldwork begins.
| Buyer Question | Red Flag Answer | Stronger Answer |
| How do you localize the research design? | “We translate the survey and field it everywhere.” | “We assess cultural interpretation, category familiarity, survey length tolerance, local fieldwork risk, and respondent comprehension before launch.” |
| How do you protect comparability across markets? | “We use the exact same questionnaire and quotas globally.” | “We preserve core metrics while adapting execution where needed so each market produces comparable, decision-ready data.” |
| How do you validate quality market by market? | “We apply our standard quality checks globally.” | “We apply consistent standards but monitor source performance, fraud risk, respondent behavior, and incidence patterns separately by market.” |
| What happens if one market lags? | “We add more sources to complete the quota.” | “We diagnose local incidence, source performance, qualification, and localization issues before altering sample design or criteria.” |
| How do you reduce cultural response bias? | “The translated questionnaire is approved.” | “We review question interpretation, scale usage, response style, local category context, and respondent relevance.” |
This rubric helps buyers move beyond the promise of global reach and evaluate whether a partner can govern quality market by market.
Operationalizing Cross-Market Quality
The best global research partners treat local variation as a quality variable, not an inconvenience.
At Borderless Access, cross-market research quality is managed as an integrated operating model. Global consistency is protected through localized execution discipline, from market-level feasibility assessment and respondent validation to source monitoring, quality controls, and human review.
Borderless Access’ panel ecosystem spans 40 markets across consumer, B2B, healthcare, and niche audiences. But scale is only the starting point. Scale becomes valuable when it is governed. For multi-country research, that means evaluating feasibility market by market, validating respondent relevance by audience type, monitoring source performance by country, and reviewing fieldwork behavior before decisions are made.
QMan, Borderless Access’ proprietary data quality framework, strengthens this operating model by monitoring survey integrity and detecting quality risks through controls such as digital fingerprinting, geolocation checks, VPN blockers, duplication prevention, behavioral scoring, and AI and ML-driven fraud detection. These controls help ensure that quality is not treated as a final-stage data cleaning exercise, but as a discipline across recruitment, survey launch, fieldwork, and post-field validation.
AI and technology provide speed and signal detection, but human review provides the context. A quality flag in one market may require a different operational response than the same flag in another. A low-incidence audience may need a market-specific recruitment strategy, not a wider programmatic net. A translated survey may need local interpretation review before launch. A source that performs well in one country may require closer scrutiny in another.
Cross-market research cannot be executed with a rigid global template. It requires a governed operating model.
The Next Standard for Global Research

Brands will always need to compare markets, track shifts, test ideas, identify growth opportunities, and make cross-regional decisions. But the future of global market research will belong to partners who can protect the integrity of the business question across entirely different market realities.
Do not ask only whether a partner can field globally. Ask how they govern translation for meaning. Ask how they monitor sample quality by country. Ask what happens when incidence shifts locally. Ask how source performance is evaluated market by market. Ask how response patterns are interpreted. Ask what evidence is available after fieldwork to support confidence in the data.
The strongest multi-country research does not choose between global consistency and local accuracy. It protects both.
That is the standard Borderless Access believes global research should meet: localized understanding, verified respondents, governed execution, and decision-ready data that can be compared with confidence.
Stop guessing at market-level risks. The Borderless Access Multi-Country Research Quality Scorecard can help buyers evaluate localized feasibility, sample source consistency, respondent validation, quality monitoring by country, comparability safeguards, and post-field quality evidence before launching the next global study.



