


In 2026, the most important question in online research is no longer simply:
Can you reach this audience?
It is: Can we trust that the people behind the data are real, relevant, and authentically engaged?
That question now sits at the center of research data quality. Across the USA, UK, and EU, research buyers are facing a sharper quality challenge: AI-generated survey responses, organized survey farms, professional respondents, VPN masking, duplicate identities, identity spoofing, and synthetic respondent risk.
The issue is not that fraud exists. Fraud has always existed in some form.
The issue is that fraud has become more scalable, more adaptive, and harder to detect with traditional checks alone.

For research directors, insights leaders, procurement teams, MR agencies, sample buyers, and panel managers, this creates a new mandate: sample quality can no longer be treated as a final-stage data cleaning task. It must be managed as a lifecycle discipline.
Bad Data Has Become a Business Risk

Poor research data quality does not stay inside a dataset. It travels into brand tracking, segmentation, concept testing, pricing studies, market entry decisions, CX programs, product development, and campaign planning.
The Insights Association states that poor data quality undermines the industry’s ability to inform smart marketing and business decisions. Its 2023-member survey found that 63% accept some level of fraud as part of conducting market research studies, 64% have experienced a project delay or negative impact due to fraud, and 56% report that fraud has affected decision-making.
That changes the conversation.
Survey fraud is not just an operations issue. It is a decision-risk issue.
A weak respondent base can make a poor idea look promising. It can inflate purchase intent. It can distort willingness to pay. It can misread brand advocacy. It can make a niche audience look larger, more available, or more positive than it really is.
For senior buyers, the real risk is not “some bad completes.”
The real risk is making confident decisions from contaminated evidence.
Why Traditional Fraud Detection is No Longer Enough
Traditional fraud detection was built around visible behavior: speeding, straight-lining, duplicate IPs, failed attention checks, inconsistent responses, and poor open ends.
These checks still matter. But they are no longer sufficient.
NORC at the University of Chicago described survey fraud in 2026 as “structural, not incidental”, warning that systems built for speed and scale were not necessarily built for identity verification. Source: NORC
That line matters because it reframes the problem.
If fraud enters at recruitment, downstream cleaning can only do so much. If professional respondents learn how to pass screeners, basic qualification is not enough. If AI can produce fluent open-ended answers, readability is not proof of authenticity. If VPNs and device masking hide location and identity signals, a completed survey may look valid while still being risky.
The new quality crisis is this: Bad data can now look clean.
What the Evidence is Telling Research Buyers
Pew Research Center found that widely used online opt-in sources contained about 4% to 7% bogus respondents, depending on the source. More importantly, Pew found that bogus respondents were not merely adding random noise. They created systematic bias by tending to select positive responses. Source: Pew Research Center
That is highly relevant for commercial research.
If low-quality or bogus respondents lean positive, they can inflate:
- Purchase intent
- Brand preference
- Product appeal
- Willingness to pay
- Claimed category behavior
- Message resonance
- Satisfaction or advocacy
- Interest in new concepts
Pew also warned in 2026 that AI and bad actors can exploit opt-in surveys because fake identities are easier to create online.
Greenbook’s 2026 GRIT reporting points in the same direction: quality infrastructure remains essential, with trusted panels and fraud detection still critical in AI-driven research.
The industry signal is clear: the future of online research will not be won by suppliers who only promise speed. It will be won by partners who can make quality visible, explainable, and governed.
The Shift: From Fraud Detection to Respondent Authenticity Governance

Most suppliers can say they have fraud checks.
That is no longer enough.
The better standard is respondent authenticity governance.
Fraud detection asks:
Did this respondent fail a check?
Respondent authenticity governance asks:
Do we have enough evidence to trust this respondent, this source, this response, and this dataset for the decision being made?
That is a higher bar. It requires quality controls across the full research lifecycle, not only at the point of survey completion.
For buyers, this means supplier evaluation needs to move beyond cost per complete, feasibility, and speed. Those still matter, but they do not answer the most important question:
What quality risk are we accepting, and how is that risk being reduced?
What a Modern Quality Framework Should Include
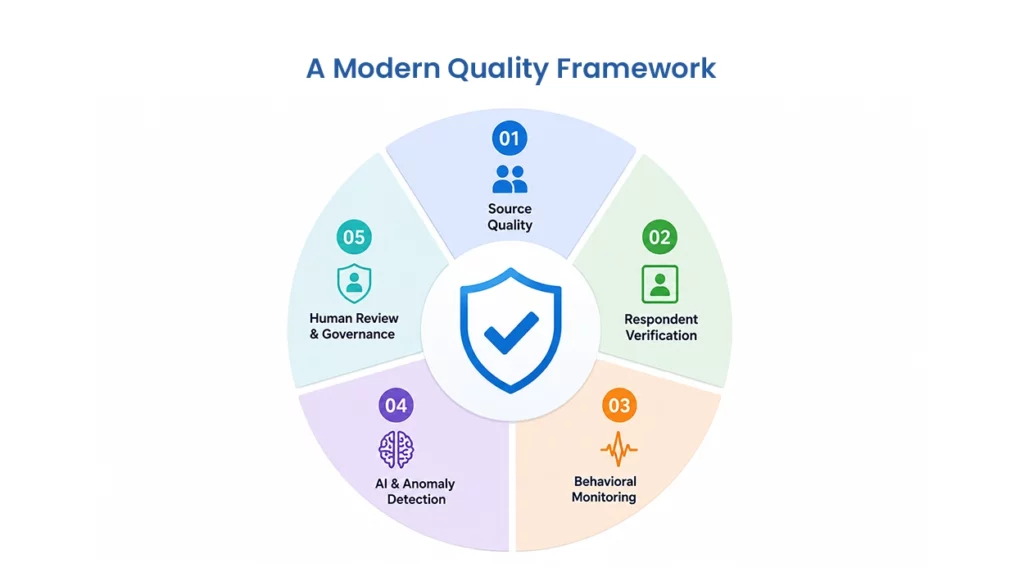
A stronger approach to research panel quality should operate across five layers.
1. Source Quality
Quality begins before fieldwork.
Research buyers should understand where respondents come from, how they are recruited, how sources are monitored, and how source quality changes over time.
ESOMAR’s online sample buyer guidance exists to help buyers determine whether a provider’s practices and samples “fit with their research objectives.”
That is the right standard. Sample is not interchangeable. A low-risk general population study, a B2B decision-maker study, a healthcare professional study, and a multi-country tracker do not carry the same validation requirements.
2. Respondent Verification
A screener is not verification.
Modern respondent validation should look at identity signals, profile consistency, device signals, location indicators, participation patterns, and eligibility fit.
The goal is not to create friction for genuine respondents. The goal is to reduce the chance that low intent, misrepresented, duplicate, or fraudulent respondents enter the research environment.
3. In-Survey Behavioral Monitoring
Speeding, straight-lining, failed logic checks, poor open ends, duplicate attempts, and inconsistent answers remain important.
But they should be treated as signals in a broader quality system. One failed check may not tell the whole story. One passed check should not create false confidence.
Patterns matter.
4. AI And Tech-Enabled Anomaly Detection
AI has made survey fraud harder. It should also make defence stronger.
AI and tech-enabled research operations can help identify response similarity, suspicious open-ended patterns, unusual device or location behavior, source-level shifts, and repeated behavior patterns.
But AI should not replace human research judgment. It should strengthen it.
5. Human Review and Quality Governance
Quality risk is contextual.
A pricing study, a healthcare study, a B2B targeting study, and a brand tracker each require various levels of scrutiny. Human review is needed to interpret exceptions, monitor sources, challenge suspicious patterns, and decide when quality trade-offs are unacceptable.
The strongest quality systems combine technology, data signals, and research judgment.
The Borderless Access View: Quality is a Lifecycle Discipline
Our view is straightforward: Sample quality is not a post-field cleaning exercise. It is an end-to-end operating discipline.
That thinking is reflected in QMan: Data Quality Framework, our multi-layer approach to protecting audience reliability, response integrity, and data confidence across the research lifecycle. QMan framework is operating across recruitment, survey launch, and post-survey engagement. The framework includes controls such as digital fingerprinting, geo-validation, VPN checks, attention checks, LOI monitoring, duplication prevention, smart sampling, machine learning-driven behavior prediction, and engagement scoring. QMan’s recruitment layer analyzes 250+ device parameters to help detect bot networks and synthetic identities.
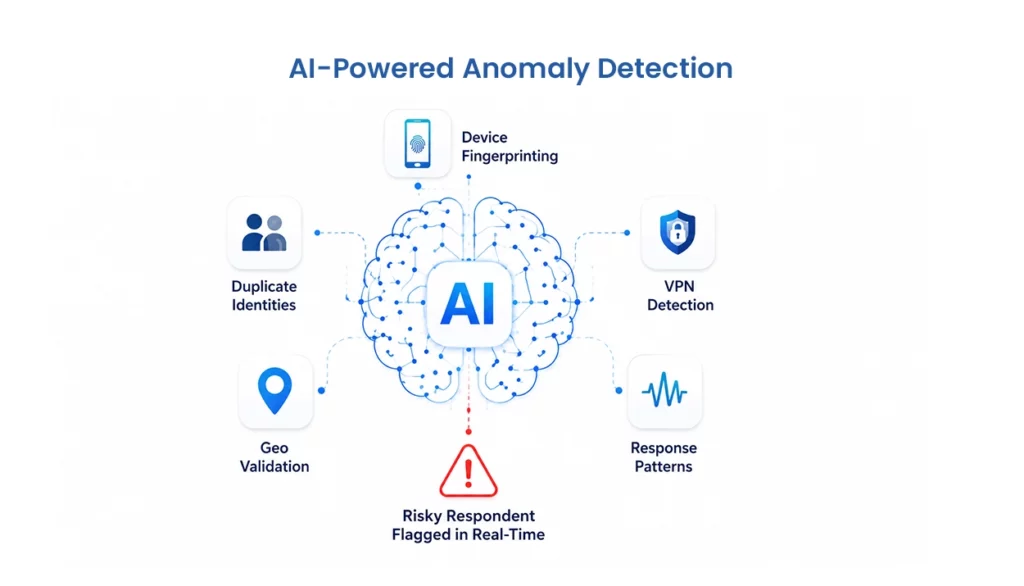
This is the distinction buyers should care about.
Not: “Do you have quality checks?”
But: “Where does validation begin, how does it continue during fieldwork, and how is respondent quality monitored after completion?”
That is where QMan, AI and tech-enabled research operations, validation frameworks, feasibility intelligence, and human review work together as a quality discipline.
What Buyers Should Ask Before Their Next Study
Before selecting a sample or audience access partner, research buyers should ask:
- Where does respondent validation begin?
- How do you verify location, identity, and device signals?
- How do you detect duplicate respondents, VPN masking, or suspicious devices?
- How do you identify AI-generated or low-authenticity open ends?
- How do you monitor respondent behavior during fieldwork?
- How do you evaluate source-level quality over time?
- What happens when a respondent or source fails quality standards?
- How do quality controls differ for B2B, healthcare, and general population research
- What quality evidence can you share after fieldwork?
- How do you balance speed, feasibility, cost, and validation?
If a supplier cannot answer these clearly, the buyer is carrying hidden quality risk.
What This Means for Procurement, Insights, and Agencies
For procurement teams, the cheapest complete may become the most expensive decision if it leads to re-fielding, delays, stakeholder doubt, or unreliable recommendations.
For insights leaders, the risk is confidence. If stakeholders lose trust in the data, they lose trust in the insights function.
For MR agencies and sample buyers, the risk is client credibility. A study can be delivered on time and still fail if the respondent base is weak.
That is why the supplier conversation needs to change.
From: “How fast can you deliver?”
To: “How do you protect the decision this research is meant to support?”
The Future of Online Research Quality
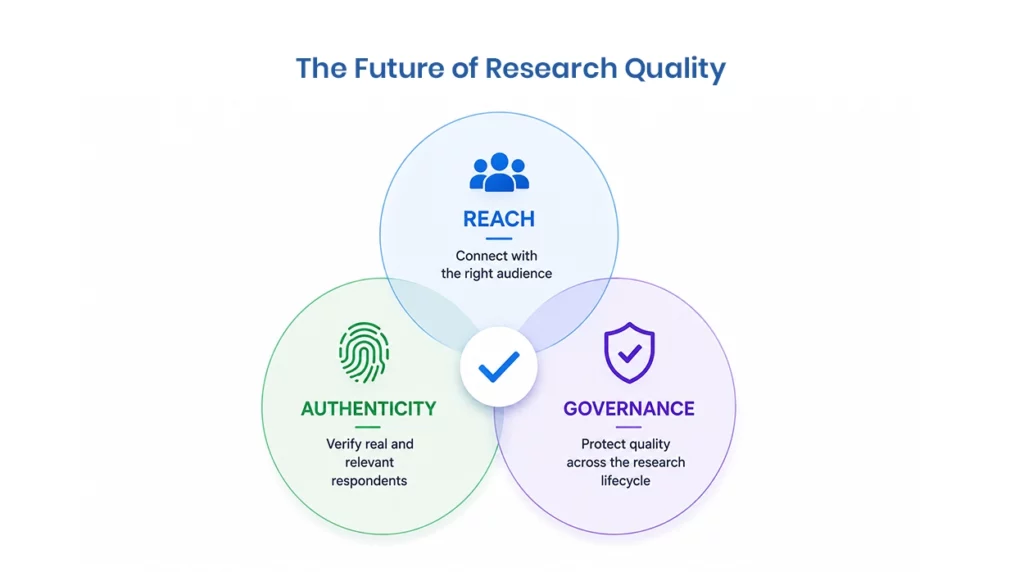
The next era of online research will reward partners who can do three things well:
- Reach the right people
- Prove those people are real and relevant
- Govern quality across the full research lifecycle
Traditional fraud detection will remain necessary. But it cannot carry the full burden of trust anymore.
Research buyers need more than claims. They need visible quality systems, transparent validation methods, and partners who understand that respondent authenticity is now central to business decision confidence.
If your team is planning research across the USA, UK, or EU, Borderless Access can help you assess respondent authenticity, sample quality, and validation risk before your next study goes live.



